
- Download Price:
- Free
- Dll Description:
- Macro Operations Module
- Versions:
- Size:
- 0.05 MB
- Operating Systems:
- Developers:
- Directory:
- M
- Downloads:
- 953 times.
Macrorec.dll Explanation
Macrorec.dll, is a dll file developed by Interact Commerce Corporation.
The Macrorec.dll file is 0.05 MB. The download links have been checked and there are no problems. You can download it without a problem. Currently, it has been downloaded 953 times.
Table of Contents
- Macrorec.dll Explanation
- Operating Systems That Can Use the Macrorec.dll File
- All Versions of the Macrorec.dll File
- Guide to Download Macrorec.dll
- How to Fix Macrorec.dll Errors?
- Method 1: Copying the Macrorec.dll File to the Windows System Folder
- Method 2: Copying the Macrorec.dll File to the Software File Folder
- Method 3: Uninstalling and Reinstalling the Software That Is Giving the Macrorec.dll Error
- Method 4: Solving the Macrorec.dll Problem by Using the Windows System File Checker (scf scannow)
- Method 5: Getting Rid of Macrorec.dll Errors by Updating the Windows Operating System
- Most Seen Macrorec.dll Errors
- Other Dll Files Used with Macrorec.dll
Operating Systems That Can Use the Macrorec.dll File
All Versions of the Macrorec.dll File
The last version of the Macrorec.dll file is the 6.0.0.679 version.This dll file only has one version. There is no other version that can be downloaded.
- 6.0.0.679 - 32 Bit (x86) Download directly this version
Guide to Download Macrorec.dll
- Click on the green-colored "Download" button (The button marked in the picture below).
Step 1:Starting the download process for Macrorec.dll - After clicking the "Download" button at the top of the page, the "Downloading" page will open up and the download process will begin. Definitely do not close this page until the download begins. Our site will connect you to the closest DLL Downloader.com download server in order to offer you the fastest downloading performance. Connecting you to the server can take a few seconds.
How to Fix Macrorec.dll Errors?
ATTENTION! In order to install the Macrorec.dll file, you must first download it. If you haven't downloaded it, before continuing on with the installation, download the file. If you don't know how to download it, all you need to do is look at the dll download guide found on the top line.
Method 1: Copying the Macrorec.dll File to the Windows System Folder
- The file you will download is a compressed file with the ".zip" extension. You cannot directly install the ".zip" file. Because of this, first, double-click this file and open the file. You will see the file named "Macrorec.dll" in the window that opens. Drag this file to the desktop with the left mouse button. This is the file you need.
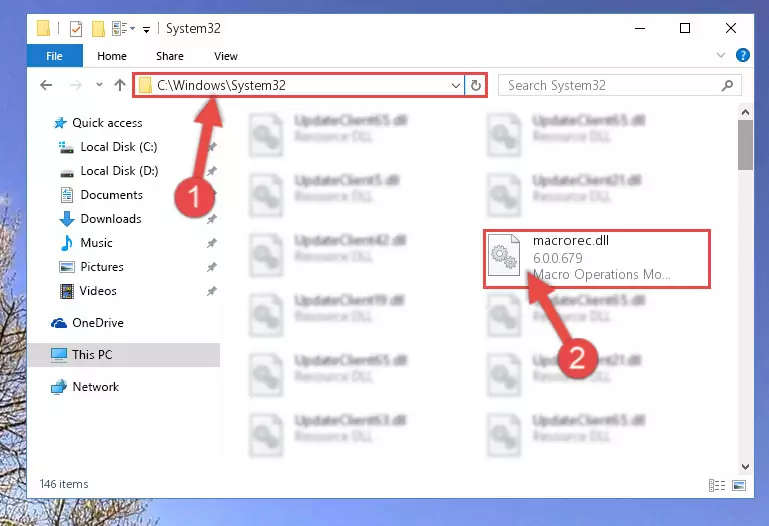
Step 1:Extracting the Macrorec.dll file from the .zip file - Copy the "Macrorec.dll" file you extracted and paste it into the "C:\Windows\System32" folder.
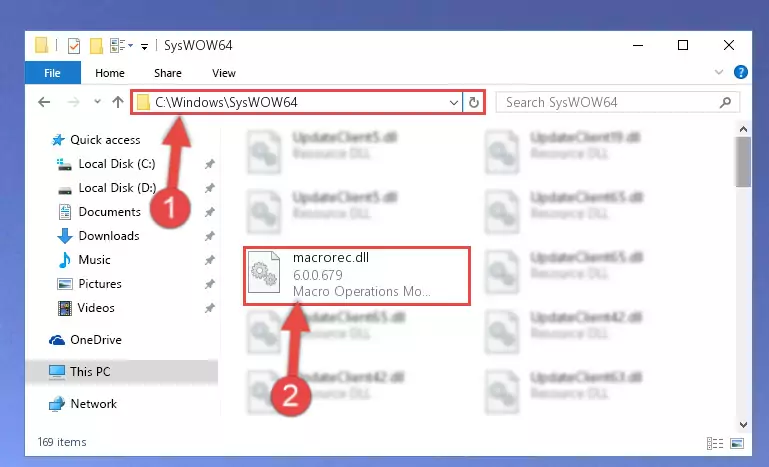
Step 2:Copying the Macrorec.dll file into the Windows/System32 folder - If you are using a 64 Bit operating system, copy the "Macrorec.dll" file and paste it into the "C:\Windows\sysWOW64" as well.
NOTE! On Windows operating systems with 64 Bit architecture, the dll file must be in both the "sysWOW64" folder as well as the "System32" folder. In other words, you must copy the "Macrorec.dll" file into both folders.
Step 3:Pasting the Macrorec.dll file into the Windows/sysWOW64 folder - In order to run the Command Line as an administrator, complete the following steps.
NOTE! In this explanation, we ran the Command Line on Windows 10. If you are using one of the Windows 8.1, Windows 8, Windows 7, Windows Vista or Windows XP operating systems, you can use the same methods to run the Command Line as an administrator. Even though the pictures are taken from Windows 10, the processes are similar.
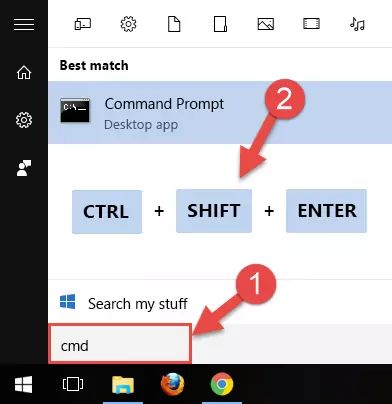
- First, open the Start Menu and before clicking anywhere, type "cmd" but do not press Enter.
- When you see the "Command Line" option among the search results, hit the "CTRL" + "SHIFT" + "ENTER" keys on your keyboard.
- A window will pop up asking, "Do you want to run this process?". Confirm it by clicking to "Yes" button.
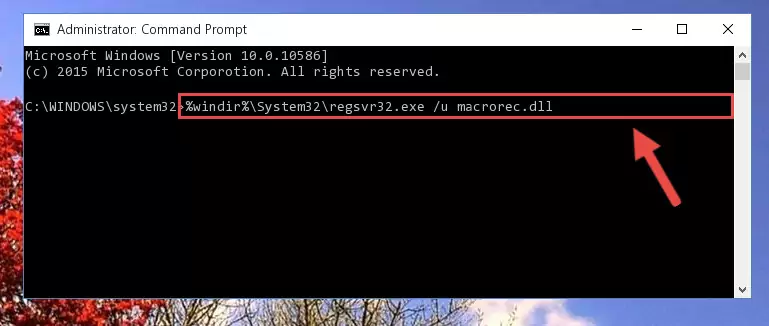
Step 4:Running the Command Line as an administrator - Paste the command below into the Command Line that will open up and hit Enter. This command will delete the damaged registry of the Macrorec.dll file (It will not delete the file we pasted into the System32 folder; it will delete the registry in Regedit. The file we pasted into the System32 folder will not be damaged).
%windir%\System32\regsvr32.exe /u Macrorec.dll
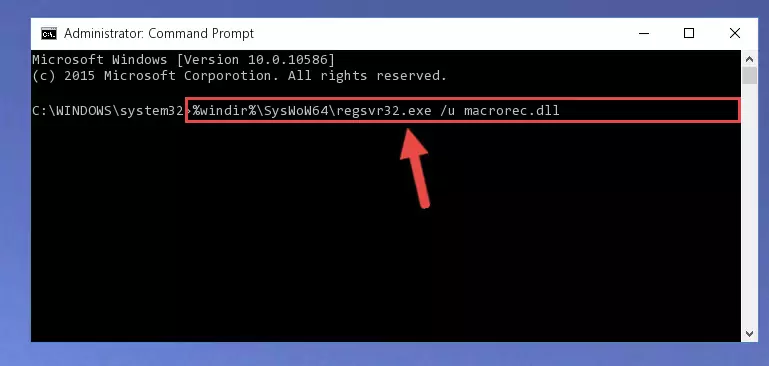
Step 5:Deleting the damaged registry of the Macrorec.dll - If you are using a Windows version that has 64 Bit architecture, after running the above command, you need to run the command below. With this command, we will clean the problematic Macrorec.dll registry for 64 Bit (The cleaning process only involves the registries in Regedit. In other words, the dll file you pasted into the SysWoW64 will not be damaged).
%windir%\SysWoW64\regsvr32.exe /u Macrorec.dll
Step 6:Uninstalling the Macrorec.dll file's problematic registry from Regedit (for 64 Bit) - You must create a new registry for the dll file that you deleted from the registry editor. In order to do this, copy the command below and paste it into the Command Line and hit Enter.
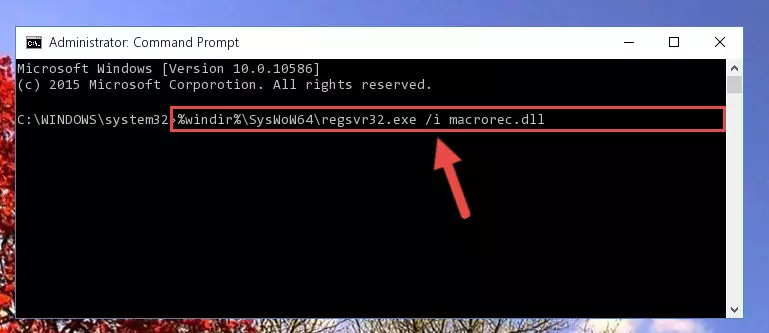
%windir%\System32\regsvr32.exe /i Macrorec.dll
Step 7:Creating a new registry for the Macrorec.dll file - Windows 64 Bit users must run the command below after running the previous command. With this command, we will create a clean and good registry for the Macrorec.dll file we deleted.
%windir%\SysWoW64\regsvr32.exe /i Macrorec.dll
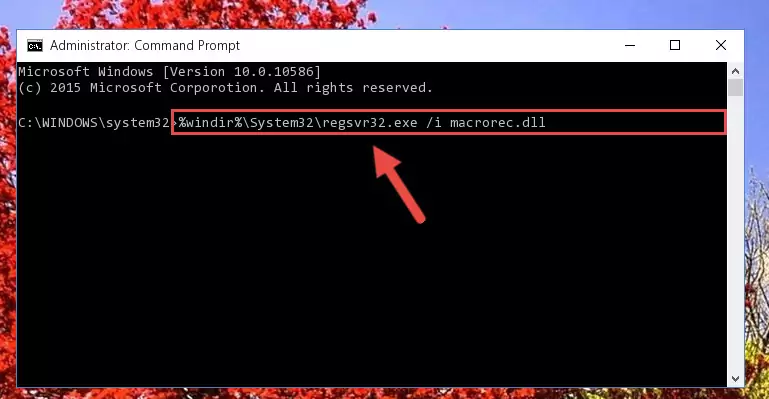
Step 8:Creating a clean and good registry for the Macrorec.dll file (64 Bit için) - If you did all the processes correctly, the missing dll file will have been installed. You may have made some mistakes when running the Command Line processes. Generally, these errors will not prevent the Macrorec.dll file from being installed. In other words, the installation will be completed, but it may give an error due to some incompatibility issues. You can try running the program that was giving you this dll file error after restarting your computer. If you are still getting the dll file error when running the program, please try the 2nd method.
Method 2: Copying the Macrorec.dll File to the Software File Folder
- In order to install the dll file, you need to find the file folder for the software that was giving you errors such as "Macrorec.dll is missing", "Macrorec.dll not found" or similar error messages. In order to do that, Right-click the software's shortcut and click the Properties item in the right-click menu that appears.
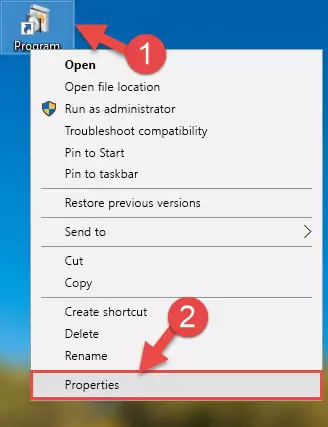
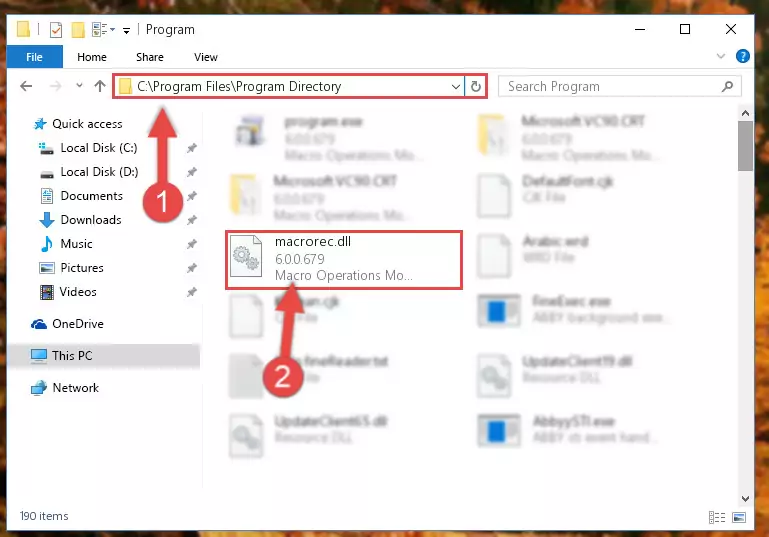
Step 1:Opening the software shortcut properties window - Click on the Open File Location button that is found in the Properties window that opens up and choose the folder where the application is installed.
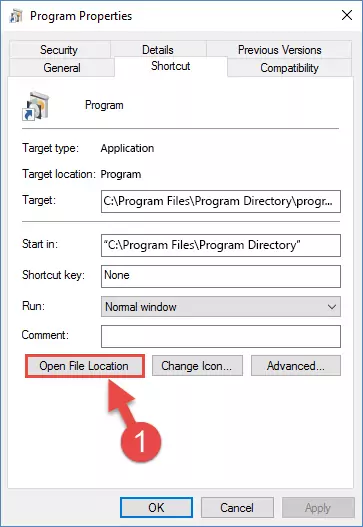
Step 2:Opening the file folder of the software - Copy the Macrorec.dll file into the folder we opened up.
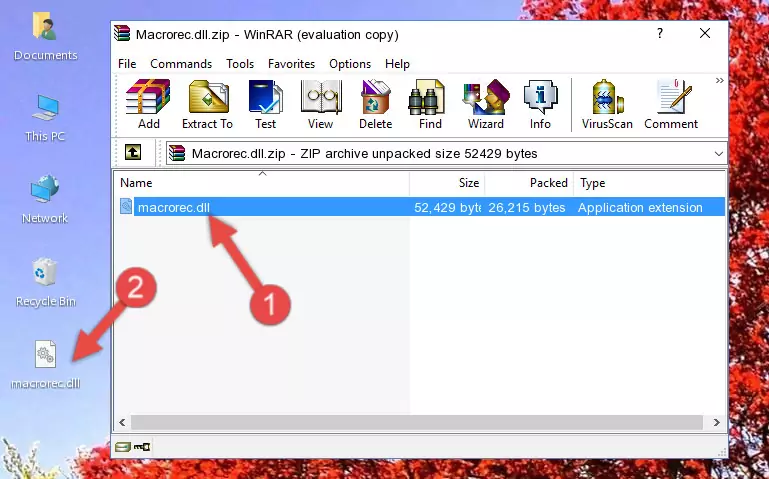
Step 3:Copying the Macrorec.dll file into the software's file folder - That's all there is to the installation process. Run the software giving the dll error again. If the dll error is still continuing, completing the 3rd Method may help solve your problem.
Method 3: Uninstalling and Reinstalling the Software That Is Giving the Macrorec.dll Error
- Push the "Windows" + "R" keys at the same time to open the Run window. Type the command below into the Run window that opens up and hit Enter. This process will open the "Programs and Features" window.
appwiz.cpl
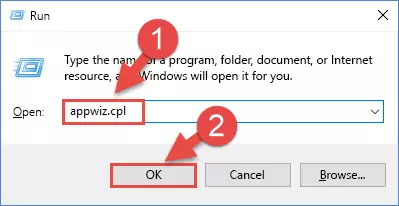
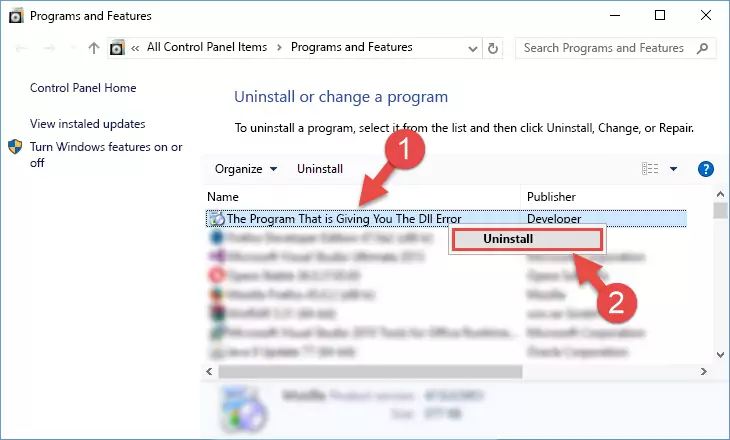
Step 1:Opening the Programs and Features window using the appwiz.cpl command - The Programs and Features screen will come up. You can see all the softwares installed on your computer in the list on this screen. Find the software giving you the dll error in the list and right-click it. Click the "Uninstall" item in the right-click menu that appears and begin the uninstall process.
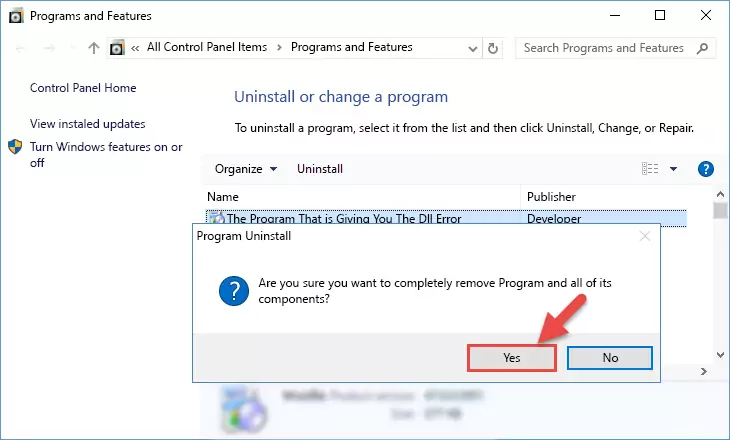
Step 2:Starting the uninstall process for the software that is giving the error - A window will open up asking whether to confirm or deny the uninstall process for the software. Confirm the process and wait for the uninstall process to finish. Restart your computer after the software has been uninstalled from your computer.
Step 3:Confirming the removal of the software - 4. After restarting your computer, reinstall the software that was giving you the error.
- You may be able to solve the dll error you are experiencing by using this method. If the error messages are continuing despite all these processes, we may have a problem deriving from Windows. To solve dll errors deriving from Windows, you need to complete the 4th Method and the 5th Method in the list.
Method 4: Solving the Macrorec.dll Problem by Using the Windows System File Checker (scf scannow)
- In order to run the Command Line as an administrator, complete the following steps.
NOTE! In this explanation, we ran the Command Line on Windows 10. If you are using one of the Windows 8.1, Windows 8, Windows 7, Windows Vista or Windows XP operating systems, you can use the same methods to run the Command Line as an administrator. Even though the pictures are taken from Windows 10, the processes are similar.
- First, open the Start Menu and before clicking anywhere, type "cmd" but do not press Enter.
- When you see the "Command Line" option among the search results, hit the "CTRL" + "SHIFT" + "ENTER" keys on your keyboard.
- A window will pop up asking, "Do you want to run this process?". Confirm it by clicking to "Yes" button.
Step 1:Running the Command Line as an administrator - Paste the command below into the Command Line that opens up and hit the Enter key.
sfc /scannow
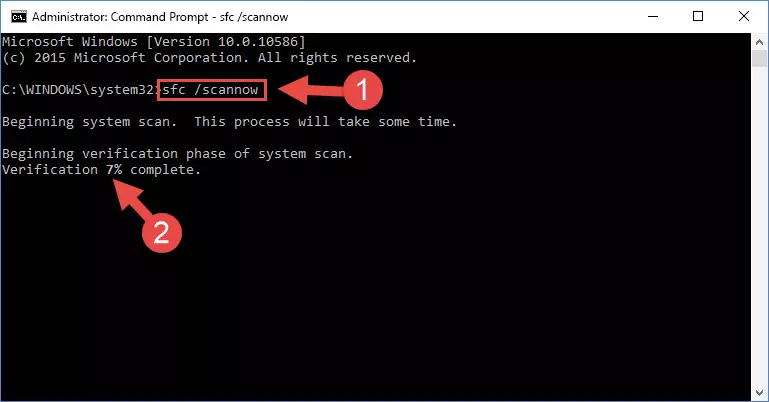
Step 2:Scanning and fixing system errors with the sfc /scannow command - This process can take some time. You can follow its progress from the screen. Wait for it to finish and after it is finished try to run the software that was giving the dll error again.
Method 5: Getting Rid of Macrorec.dll Errors by Updating the Windows Operating System
Some softwares require updated dll files from the operating system. If your operating system is not updated, this requirement is not met and you will receive dll errors. Because of this, updating your operating system may solve the dll errors you are experiencing.
Most of the time, operating systems are automatically updated. However, in some situations, the automatic updates may not work. For situations like this, you may need to check for updates manually.
For every Windows version, the process of manually checking for updates is different. Because of this, we prepared a special guide for each Windows version. You can get our guides to manually check for updates based on the Windows version you use through the links below.
Windows Update Guides
Most Seen Macrorec.dll Errors
It's possible that during the softwares' installation or while using them, the Macrorec.dll file was damaged or deleted. You can generally see error messages listed below or similar ones in situations like this.
These errors we see are not unsolvable. If you've also received an error message like this, first you must download the Macrorec.dll file by clicking the "Download" button in this page's top section. After downloading the file, you should install the file and complete the solution methods explained a little bit above on this page and mount it in Windows. If you do not have a hardware problem, one of the methods explained in this article will solve your problem.
- "Macrorec.dll not found." error
- "The file Macrorec.dll is missing." error
- "Macrorec.dll access violation." error
- "Cannot register Macrorec.dll." error
- "Cannot find Macrorec.dll." error
- "This application failed to start because Macrorec.dll was not found. Re-installing the application may fix this problem." error