
- Download Price:
- Free
- Dll Description:
- STYLUS Setup Resource DLL
- Versions:
- Size:
- 0.02 MB
- Operating Systems:
- Directory:
- 2
- Downloads:
- 1064 times.
What is 21755b7.dll? What Does It Do?
The size of this dll file is 0.02 MB and its download links are healthy. It has been downloaded 1064 times already.
Table of Contents
- What is 21755b7.dll? What Does It Do?
- Operating Systems Compatible with the 21755b7.dll File
- All Versions of the 21755b7.dll File
- Steps to Download the 21755b7.dll File
- How to Install 21755b7.dll? How to Fix 21755b7.dll Errors?
- Method 1: Installing the 21755b7.dll File to the Windows System Folder
- Method 2: Copying The 21755b7.dll File Into The Software File Folder
- Method 3: Doing a Clean Reinstall of the Software That Is Giving the 21755b7.dll Error
- Method 4: Solving the 21755b7.dll Problem by Using the Windows System File Checker (scf scannow)
- Method 5: Fixing the 21755b7.dll Errors by Manually Updating Windows
- Our Most Common 21755b7.dll Error Messages
- Dll Files Similar to the 21755b7.dll File
Operating Systems Compatible with the 21755b7.dll File
All Versions of the 21755b7.dll File
The last version of the 21755b7.dll file is the 3.1.0.08 version.This dll file only has one version. There is no other version that can be downloaded.
- 3.1.0.08 - 32 Bit (x86) Download directly this version
Steps to Download the 21755b7.dll File
- First, click the "Download" button with the green background (The button marked in the picture).
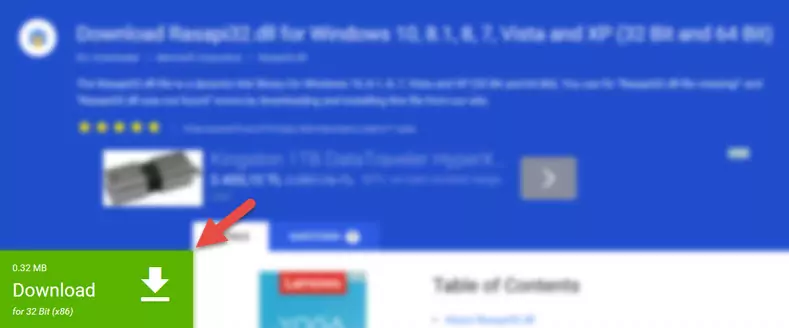
Step 1:Download the 21755b7.dll file - "After clicking the Download" button, wait for the download process to begin in the "Downloading" page that opens up. Depending on your Internet speed, the download process will begin in approximately 4 -5 seconds.
How to Install 21755b7.dll? How to Fix 21755b7.dll Errors?
ATTENTION! In order to install the 21755b7.dll file, you must first download it. If you haven't downloaded it, before continuing on with the installation, download the file. If you don't know how to download it, all you need to do is look at the dll download guide found on the top line.
Method 1: Installing the 21755b7.dll File to the Windows System Folder
- The file you are going to download is a compressed file with the ".zip" extension. You cannot directly install the ".zip" file. First, you need to extract the dll file from inside it. So, double-click the file with the ".zip" extension that you downloaded and open the file.
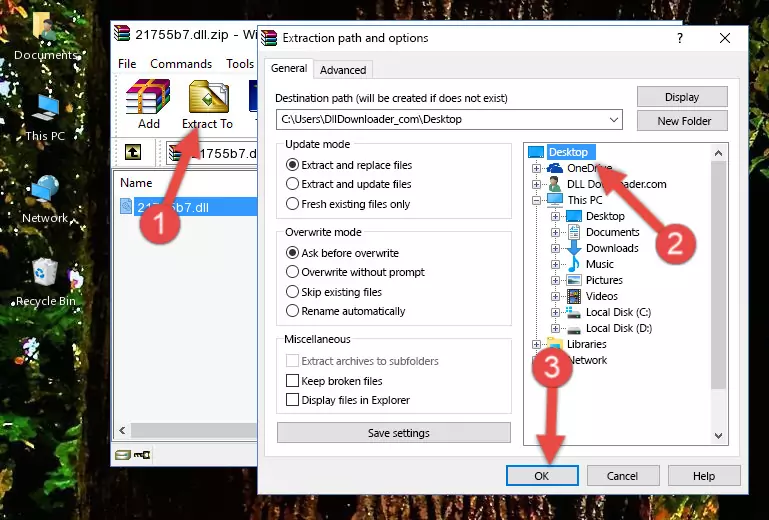
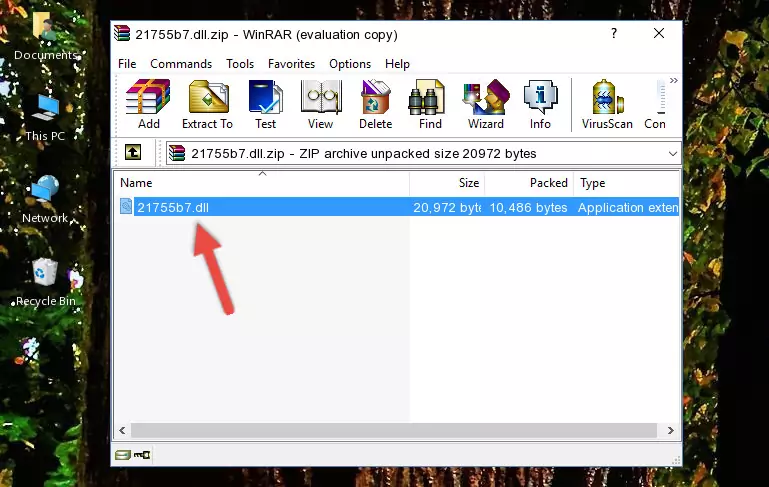
- You will see the file named "21755b7.dll" in the window that opens up. This is the file we are going to install. Click the file once with the left mouse button. By doing this you will have chosen the file.
Step 2:Choosing the 21755b7.dll file - Click the "Extract To" symbol marked in the picture. To extract the dll file, it will want you to choose the desired location. Choose the "Desktop" location and click "OK" to extract the file to the desktop. In order to do this, you need to use the Winrar software. If you do not have this software, you can find and download it through a quick search on the Internet.
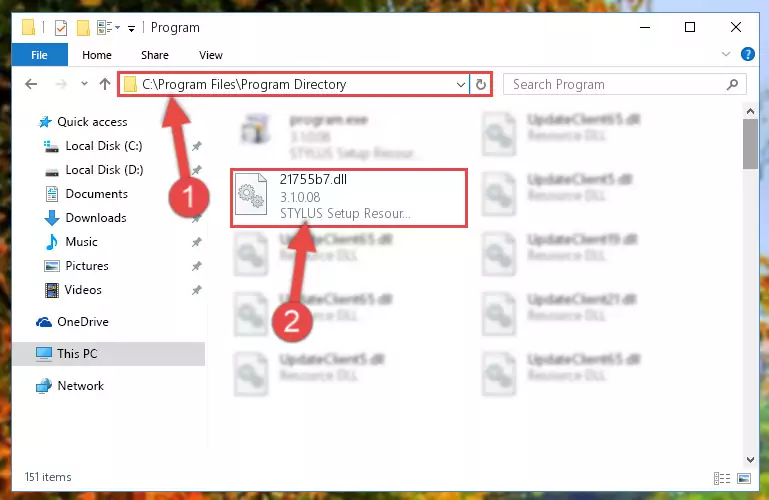
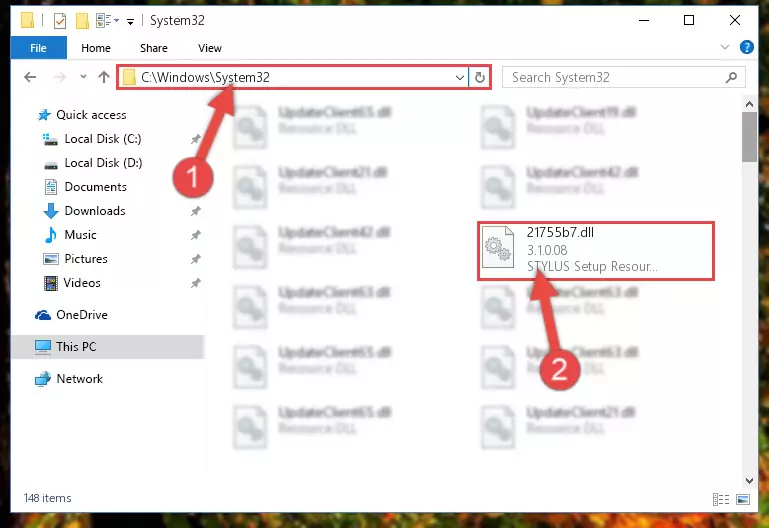
Step 3:Extracting the 21755b7.dll file to the desktop - Copy the "21755b7.dll" file and paste it into the "C:\Windows\System32" folder.
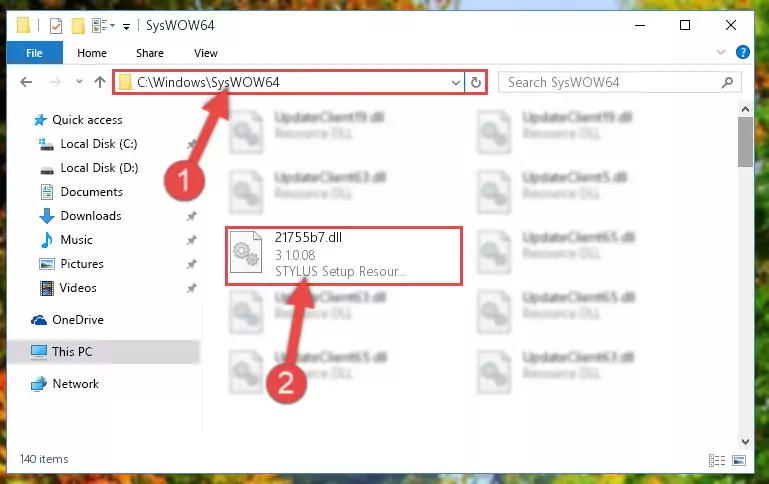
Step 4:Copying the 21755b7.dll file into the Windows/System32 folder - If you are using a 64 Bit operating system, copy the "21755b7.dll" file and paste it into the "C:\Windows\sysWOW64" as well.
NOTE! On Windows operating systems with 64 Bit architecture, the dll file must be in both the "sysWOW64" folder as well as the "System32" folder. In other words, you must copy the "21755b7.dll" file into both folders.
Step 5:Pasting the 21755b7.dll file into the Windows/sysWOW64 folder - First, we must run the Windows Command Prompt as an administrator.
NOTE! We ran the Command Prompt on Windows 10. If you are using Windows 8.1, Windows 8, Windows 7, Windows Vista or Windows XP, you can use the same methods to run the Command Prompt as an administrator.
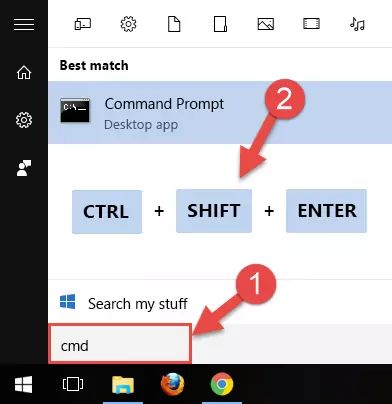
- Open the Start Menu and type in "cmd", but don't press Enter. Doing this, you will have run a search of your computer through the Start Menu. In other words, typing in "cmd" we did a search for the Command Prompt.
- When you see the "Command Prompt" option among the search results, push the "CTRL" + "SHIFT" + "ENTER " keys on your keyboard.
- A verification window will pop up asking, "Do you want to run the Command Prompt as with administrative permission?" Approve this action by saying, "Yes".
%windir%\System32\regsvr32.exe /u 21755b7.dll
%windir%\SysWoW64\regsvr32.exe /u 21755b7.dll
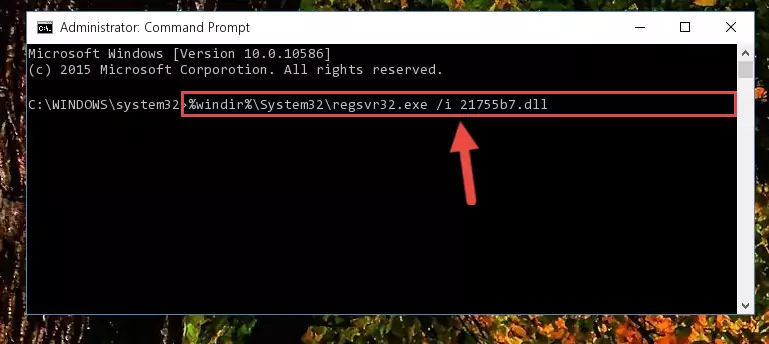
%windir%\System32\regsvr32.exe /i 21755b7.dll
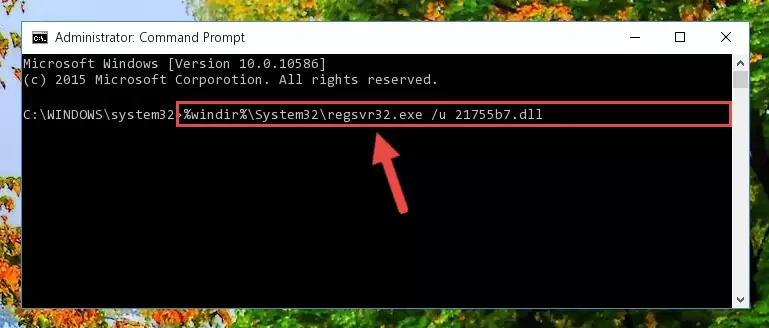
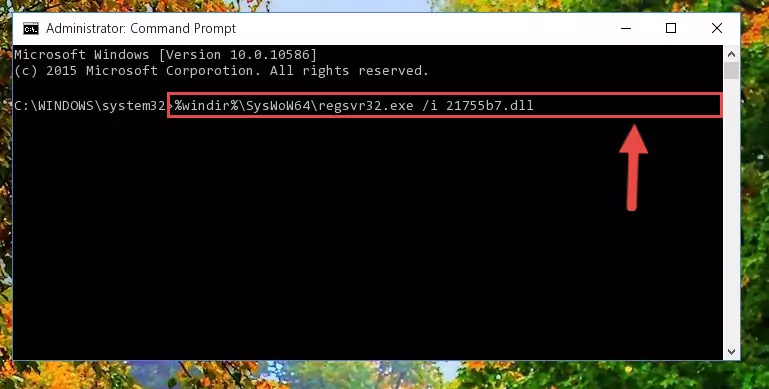
%windir%\SysWoW64\regsvr32.exe /i 21755b7.dll
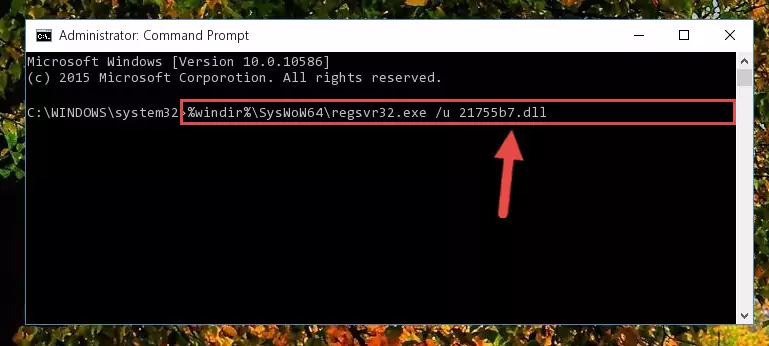
Method 2: Copying The 21755b7.dll File Into The Software File Folder
- In order to install the dll file, you need to find the file folder for the software that was giving you errors such as "21755b7.dll is missing", "21755b7.dll not found" or similar error messages. In order to do that, Right-click the software's shortcut and click the Properties item in the right-click menu that appears.
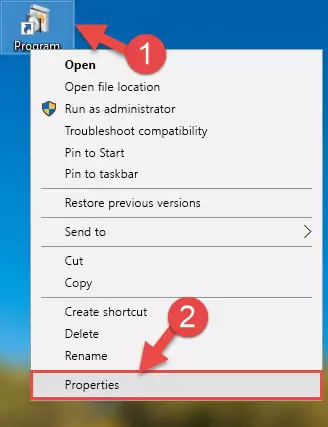
Step 1:Opening the software shortcut properties window - Click on the Open File Location button that is found in the Properties window that opens up and choose the folder where the application is installed.
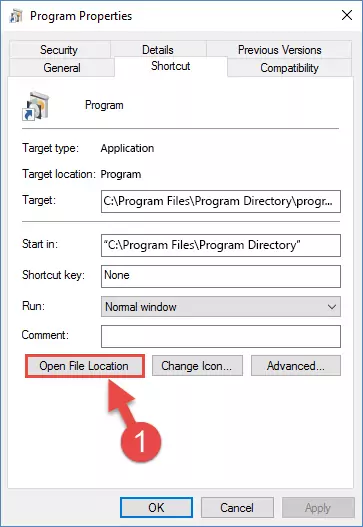
Step 2:Opening the file folder of the software - Copy the 21755b7.dll file into the folder we opened up.
Step 3:Copying the 21755b7.dll file into the software's file folder - That's all there is to the installation process. Run the software giving the dll error again. If the dll error is still continuing, completing the 3rd Method may help solve your problem.
Method 3: Doing a Clean Reinstall of the Software That Is Giving the 21755b7.dll Error
- Open the Run window by pressing the "Windows" + "R" keys on your keyboard at the same time. Type in the command below into the Run window and push Enter to run it. This command will open the "Programs and Features" window.
appwiz.cpl
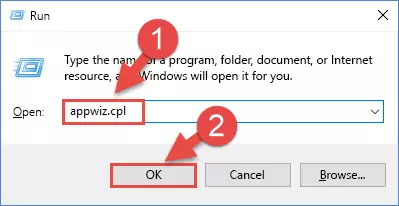
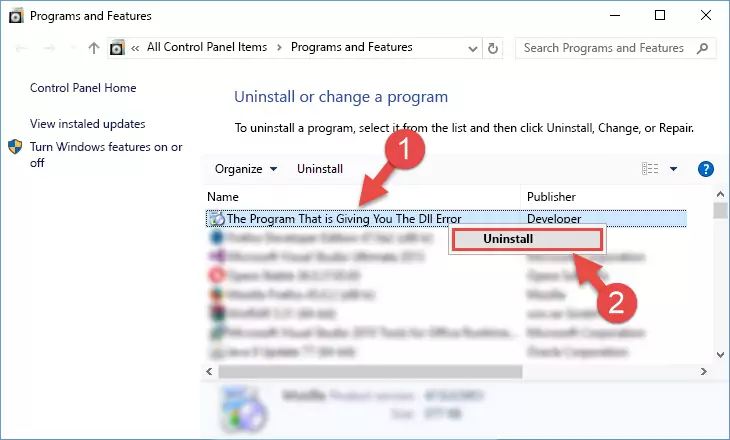
Step 1:Opening the Programs and Features window using the appwiz.cpl command - The Programs and Features screen will come up. You can see all the softwares installed on your computer in the list on this screen. Find the software giving you the dll error in the list and right-click it. Click the "Uninstall" item in the right-click menu that appears and begin the uninstall process.
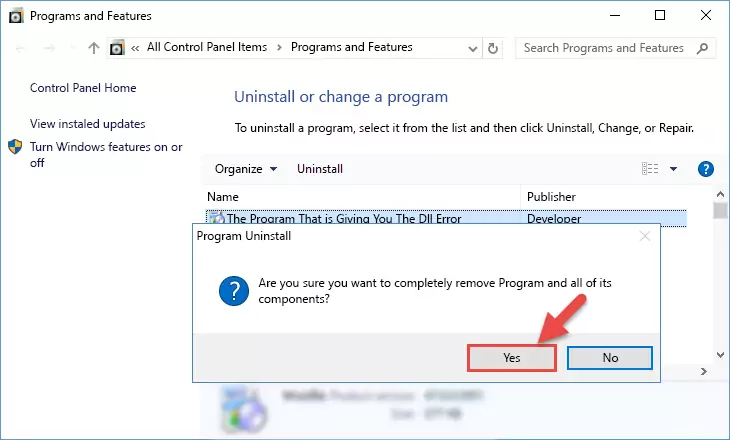
Step 2:Starting the uninstall process for the software that is giving the error - A window will open up asking whether to confirm or deny the uninstall process for the software. Confirm the process and wait for the uninstall process to finish. Restart your computer after the software has been uninstalled from your computer.
Step 3:Confirming the removal of the software - 4. After restarting your computer, reinstall the software that was giving you the error.
- You may be able to solve the dll error you are experiencing by using this method. If the error messages are continuing despite all these processes, we may have a problem deriving from Windows. To solve dll errors deriving from Windows, you need to complete the 4th Method and the 5th Method in the list.
Method 4: Solving the 21755b7.dll Problem by Using the Windows System File Checker (scf scannow)
- First, we must run the Windows Command Prompt as an administrator.
NOTE! We ran the Command Prompt on Windows 10. If you are using Windows 8.1, Windows 8, Windows 7, Windows Vista or Windows XP, you can use the same methods to run the Command Prompt as an administrator.
- Open the Start Menu and type in "cmd", but don't press Enter. Doing this, you will have run a search of your computer through the Start Menu. In other words, typing in "cmd" we did a search for the Command Prompt.
- When you see the "Command Prompt" option among the search results, push the "CTRL" + "SHIFT" + "ENTER " keys on your keyboard.
- A verification window will pop up asking, "Do you want to run the Command Prompt as with administrative permission?" Approve this action by saying, "Yes".
sfc /scannow
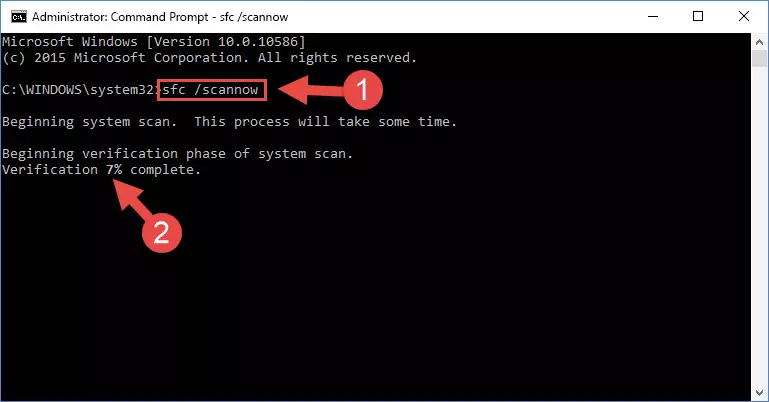
Method 5: Fixing the 21755b7.dll Errors by Manually Updating Windows
Most of the time, softwares have been programmed to use the most recent dll files. If your operating system is not updated, these files cannot be provided and dll errors appear. So, we will try to solve the dll errors by updating the operating system.
Since the methods to update Windows versions are different from each other, we found it appropriate to prepare a separate article for each Windows version. You can get our update article that relates to your operating system version by using the links below.
Guides to Manually Update for All Windows Versions
Our Most Common 21755b7.dll Error Messages
If the 21755b7.dll file is missing or the software using this file has not been installed correctly, you can get errors related to the 21755b7.dll file. Dll files being missing can sometimes cause basic Windows softwares to also give errors. You can even receive an error when Windows is loading. You can find the error messages that are caused by the 21755b7.dll file.
If you don't know how to install the 21755b7.dll file you will download from our site, you can browse the methods above. Above we explained all the processes you can do to solve the dll error you are receiving. If the error is continuing after you have completed all these methods, please use the comment form at the bottom of the page to contact us. Our editor will respond to your comment shortly.
- "21755b7.dll not found." error
- "The file 21755b7.dll is missing." error
- "21755b7.dll access violation." error
- "Cannot register 21755b7.dll." error
- "Cannot find 21755b7.dll." error
- "This application failed to start because 21755b7.dll was not found. Re-installing the application may fix this problem." error